Radiology AI
ReXrank Mini
Can AI write radiology reports from chest X-rays?
A subset of the full ReXrank evaluation suite
The Task
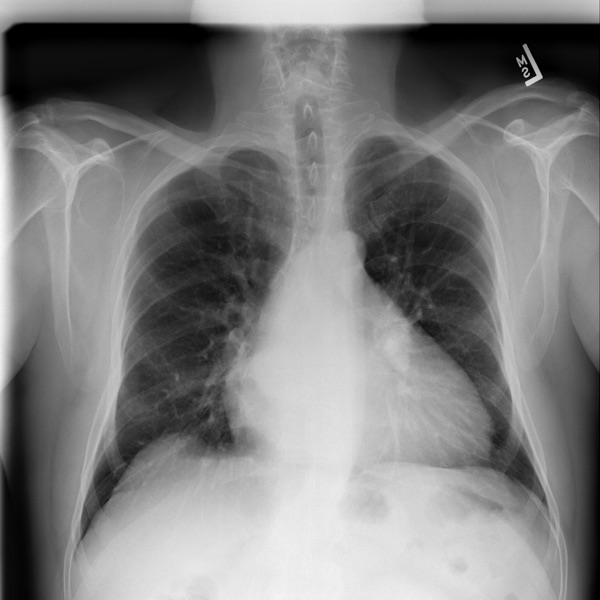
Chest X-Ray Image(s)
→Generate
Findings: Stable cardiomegaly. Increased interstitial lung markings. Small residual left basilar effusion. Stable tunneled dialysis catheter.
Impression: Stable cardiomegaly with persistent left basilar effusion.
System Prompt
You are an expert radiologist. Given the chest X-ray image(s), generate a radiology report with two sections: Findings and Impression.
Images only, no clinical context. Models receive CXR images but no patient history, indication, or prior studies -- they must interpret the images cold.
Three Public Datasets
Easiest
IU X-Ray
Indiana University
3,955
studies
Multi-view (frontal + lateral). Smallest dataset -- diverse normal/abnormal cases.
Medium
MIMIC-CXR
MIT / Beth Israel Deaconess
227K
studies
Largest public CXR dataset. Diverse pathology from a major academic medical center.
Hardest
CheXpert Plus
Stanford University
223K
studies
Includes free-text reports. Challenging cases from Stanford's radiology archives.
Same task, three different institutions. Performance varies dramatically across data sources.
ReXrank Mini evaluates on these 3 public datasets. The full ReXrank leaderboard also includes the private ReXGradient test set. AAAI 2025 paper
The Metric
GREEN
Generative Radiology Report Evaluation and Error Notation
LLM as a judge. Uses a language model to evaluate report quality -- capturing clinical meaning, not just word overlap.
Open-source and lightweight. Runs locally, no proprietary APIs required.
Single composite score. One number per report, replacing the patchwork of 7+ traditional NLP metrics.
Score: 0 to 1 -- higher is better
Traditional NLP metrics miss clinical meaning. GREEN uses an LLM to judge whether the right findings are reported -- the way a radiologist would.
What GREEN Catches
Radiologist Reference (IU X-Ray)
Findings: Stable cardiomegaly and mediastinal contour. Increased interstitial lung markings, possibly due to volume overload. Improved aeration of lung bases with small residual left basilar effusion. No focal consolidation or pneumothorax. Stable tunneled dialysis catheter. Impression: Stable cardiomegaly. Persistent left basilar effusion. Prominent interstitium.
Gemini 3.1 Pro (Rank #1 Overall)
Findings: Lungs are clear bilaterally without focal consolidation, pleural effusion, or pneumothorax. Cardiomediastinal silhouette is normal in size. A right-sided tunneled central venous catheter is present. Osseous structures are unremarkable. Impression: No acute cardiopulmonary abnormality.
Catheter -- GREEN: correct
No pneumothorax -- GREEN: correct
Cardiomegaly -- GREEN: missed finding
Effusion -- GREEN: contradicted
This is one challenging case -- not the norm. GREEN catches these clinically significant errors that traditional NLP metrics would miss. The top model still leads across hundreds of studies.
ReXrank Mini Leaderboard
Overall GREEN score across IU X-Ray, MIMIC-CXR, and CheXpert Plus. Higher is better.
Best (≥0.8)
Mid (0.6-0.8)
Low (<0.6)
| # | Model | GREEN | IU X-Ray | MIMIC-CXR | CheXpert+ | Quality |
|---|
Placeholder scores -- real GREEN evaluation in progress
R
Full ReXrank Leaderboard
rexrank.ai -- including ReXGradient private test set
Zhang et al. "ReXrank: A Public Leaderboard for AI-Powered Radiology Report Generation" -- AAAI 2025